
技术交流

扫描二维码
或添加“GeneGroup003”
获取更多更新资讯
商城订购

扫描二维码
或添加“基因商城(GeneMart)”
手机下单,快人一步
售后服务

扫描二维码
或添加“GeneGroup005”
获取更快速售后支持
HiFi测序提供高精度宏基因组结果!

环境群落中微生物种类的鉴定是微生物学的一项重要任务。Shotgun宏基因组测序可以提供这些群落中物种的相对无偏采样。由于Shotgun测序数据的复杂性导致了许多分类分析方法的发展,但此前关注的多是二代测序,即短读长测序技术。随着三代测序(长读长测序技术)的发展,人们越来越意识到三代测序提供的新机会。短读长reads通常包含一个基因片段,而长读长reads却能够跨越多个基因和基因间区域。目前最受欢迎的长读长测序平台分别是PacBio和ONT。
很少有研究评估长读长分类分析方法的性能,部分原因是很少有专门的方法可用。然而,长读长分类方法的发展速度似乎越来越快。MetaMaps和MEGANLR是最早的长读长分类方法,2021年初出现了包括MMseqs2 taxonomy和BugSeq在内的多种方法。鉴于长读长测序技术错误率的急剧下降和长读长分类方法的激增,迫切需要评估分类方法的性能。那么,哪些方法对长读长数据集表现最好?长读长是否比短读长提供更准确的分类概况或丰度估计?长读长测序质量的差异是否会对性能产生影响?我们一起来看看叭~

研究人员从公开数据库获得了两个PacBio HiFi数据集和两个ONT数据集。评估了11种方法在长读长群落数据集上的性能,包括了五种专门为长读长开发的方法、五种常用的短读长方法和一种通用方法(表1)。研究人员对长读长数据集运行了所有的方法,对人工拆分的短读长数据集只使用了短读长分析方法。
表1.本实验中使用的分类分析方法

研究人员使用几个标准来评估方法的性能,包括reads利用率、种和属水平分析,以及相对丰度估计。
结果分析
1.reads利用率
不同方法的总reads分配差异很大(图1)。就短读法而言,Kraken、Bracken和Centrifuge-h22分配的reads数量最多(HiFi为93-100%,ONT为81-99%)。Centrifuge-h500除了HiFi ATCC MSA-1003(有98%的读取分配),在数据集上分配的reads数要少得多(1-53%),甚至在ONT R10 Zymo D6300中异常低(~ 1%)。两种基于标记的分析方法都分配了最少的reads数(MetaPhlAn3: 23-39%;mOTUs2: 0.2-1%)。HiFi和ONT数据集之间的sourmash分配差异最大,HiFi中分配的数据集(81-90%)远远多于ONT (ONT R10.3为26-41%,ONT Q20为59-68%)。
在不同的长读长分析方法和不同的测序技术之间,读取分配存在相当大的差异。所有长读长分析方法中,HiFi数据集中的总reads分配范围为71%至99%(平均= 85%),而ONT的范围为46%至97%(平均= 71%)。对于ONT数据集,MetaMaps和BugSeq-V2分配的reads数最多(95-97%),其他所有方法分配的reads数较少(46-67%)。依赖于蛋白质参考数据库翻译比对的方法在HiFi数据集中比ONT数据集中分配了更多的reads,包括MMseqs2 (HiFi: 94-99%;ONT: 46-67%)和MEGAN-LR-prot (HiFi: 71-74%;ONT: 60–62%) ,因为即使是稍微高一点的错误率也会对翻译比对产生负面影响。针对MMSeqs2分析方法,ONT R10.3数据集中分配的reads数比Q20数据集中分配的少(分别为46%和67%),同样的模式也存在于Centrifuge-500和sourmash。然而,尽管ONT Q20数据集的准确性有所提高,但与HiFi数据集相比,reads分配仍然较低。

图1.各分类方法的Read利用率。A.HiFi ATCC MSA-1003, B.HiFi Zymo D6331, C.ONT R10 Zymo D6300, D. ONT Zymo D6300。
2.种、属水平分析
基于最小阈值为总reads的0.001%的物种检测结果汇总如图2、图3所示。最明显的性能差异出现在短读长和长读长/通用分析方法(包括sourmash)之间。大多数短读长分析方法显示出非常低的精度和相对较高的召回率,因此F值非常低。
长读长分析方法和sourmash在准确率、召回率和F值方面优于短读长(图2),但它们也显示出性能上的差异。有些方法没有显示一致的结果,对于特定的数据集执行得更好。例如,MetaMaps和MMseqs2在HiFi ATCC MSA-1003上表现相当好。然而,这两种方法在其他三个数据集上的表现较差,并且与短读长分析方法的结果更接近(例如,非常低的精度,较高的召回率);有趣的是,sourmash在HiFi数据集上显示出很高的精度和召回率(k51中最高),优于大多数长读长分析方法。然而,对于ONT数据集,其性能有所下降;这对于ONT R10尤其明显(图2)。
在所有四个数据集中,MEGAN-LR-prot、MEGAN-LR-nuc-HiFi、MEGAN-LR-nuc-ONT和BugSeq-V2始终表现出最佳性能(图2-3)。这四种方法检出的物种数量最多(假阴性值低),检出的假阳性值很少(0-2)。因此,它们显示出高精度、中等到高召回率和最高的F值。HiFi数据集的中等召回率是由于未能检测到丰度较低的物种,特别是0.02%至0.0001%丰度水平,而Sourmash (k31和k51)在这些具有挑战性的HiFi数据集上显示了出色的召回率。对于ONT数据集,Zymo D6300中的物种具有相对较高的丰度(12%和2%),这反映在几乎所有长读长分析方法以及sourmash的完美召回中。

图2. A.HiFi ATCC MSA-1003, B.HiFi Zymo D6331, C.ONT R10 Zymo D6300, D.ONT Q20 Zymo D6300的最小阈值为总读数的0.001%,用于物种水平分析的精密度、召回率和F值

图3.在最小阈值为总reads的0.001%的基础上,得到物种水平分析的A.精密度和召回率, B.F1分数, C.F0.5分数的平均值。B和C中竖线右侧的方法是长读分类器。
基于0.001%的最小阈值的属水平分析在精度、召回率和F值方面有一定提高(图4、5)。改进几乎是可以保证的,因为分配给一个属内多个物种的读数在属水平上都被认为是正确的,因此假阳性(和潜在的假阴性)的数量减少了。尽管在属水平上,所有方法的精度、召回率和F值都有所提高,但长读长分析方法的性能仍然大大优于大多数短读长分析方法(图5)。

图4.A.HiFi ATCC MSA-1003, B.HiFi Zymo D6331, C.ONT R10 Zymo D6300, D.ONT Q20 Zymo D6300的最小阈值为总读数的0.001%,用于属水平分析的精密度、召回率和F值
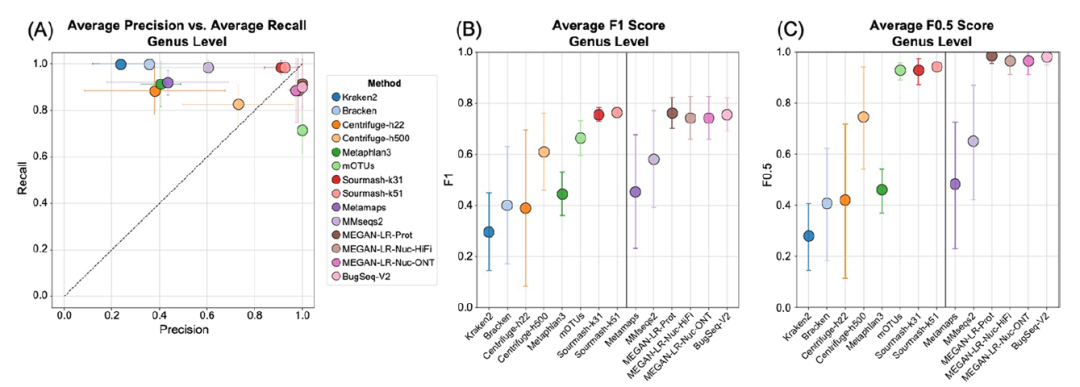
图5.在最小阈值为总reads的0.001%的基础上,得到属水平分析的A.精密度和召回率, B.F1分数, C.F0.5分数的平均值。B和C中竖线右侧的方法是长读分类器。
3.相对丰度估计
研究人员进行了物种水平和属水平的相对丰度分析,对所有数据集进行分析发现,在物种水平上,采用长读长分析方法和sourmash估算的丰度比采用短读长方法估算的丰度更准确。

图6.物种水平的相对丰度分析
另外,作者还评估了Kraken2、Bracken、Centrifuge-h22、MetaPhlAn3、mOTUs2和sourmash (k31和k51)在ATCC MSA-1003和Zymo D6300群落两种类型的短读长数据集上的性能。
从两个群体的短读长数据集中获得的精度、召回率和F值与从长读长数据集中获得的结果非常相似(图7A-B),Sourmash在短读长数据集中表现最好,具有高召回和高精度。然而,短读长数据集无法产生准确的相对丰度估计。在两个群落的种水平上,所有的短读长方法都未能通过卡方拟合优度检验(图7C-D),在属水平上,只有sourmash-k51通过了拟合优度检验。

图7.两个Illumina短读数据集的结果。a Illumina ATCC MSA-1003和B Illumina Zymo D6300的精密度、召回率和f -分数基于总读数的0.001%的最小阈值。C Illumina ATCC MSA-1003和D Illumina zimo D6300的种水平相对丰度估计。
要点讨论
1. HiFi ATCC和Zymo数据集更准确;所有读数均> Q20,中位数分别为Q36和Q40。读取质量对于使用长读长方法进行高质量的分类分析仍然至关重要。在物种总数(10 vs 17/20)和相对丰度方面,ONT的模拟群落比HiFi模拟群落更简单。更简单的模拟群落设计也使研究人员无法用ONT数据估计低丰度物种的召回率和检出限度;本文中关于低丰度检测能力的结论完全基于PacBio HiFi数据。
2. 包含较短的长读长reads(< 2 kb)可能对分类分析产生不利影响,具有显著较低的精度和F值并会严重扭曲相对丰度估计。因此,强烈建议在尝试分类之前过滤这些较短的长读长reads。这可以在测序后以生物信息学的方式实现,也可以在文库制备过程中进行筛选从而大大减少较短片段的数量。
3. 对于任何给定的群落,长读长数据集(使用sourmash或任何长读长方法分析)产生的结果明显优于短读长数据集。利用长读长数据集中存在的远程信息的方法在分类分析和丰度估计方面提供了明显的改进,并且比短读长方法显示出明显的优势。

基因有限公司作为PacBio公司中国区合作伙伴,自2011年以来将PacBio第三代单分子实时测序技术引入国内,一直为国内用户提供专业的三代测序系统的安装培训,技术支持,应用培训与售后维护工作,赢得客户的一致好评与信任。基因有限公司将一如既往的支持越来越多的PacBio用户。 关于基因 基因有限公司成立于1992年,是一家提供生命科学科研仪器、试剂耗材和技术服务的综合服务商。基于“Gene Brightens Every Life • BioTech Connects the World”——“基因燃亮生命 • 生物技术连接世界”的愿景,专注于生命科学领域前沿技术的引进和推广,致力于推动该领域国内科研机构硬件水平及实验方案的革新与升级。同时,公司也一直致力于自主品牌的科研设备的研发与生产,拥有一系列通用性强、互补性高的自主品牌产品。 基因的服务网络遍及全国各地十多个大中城市,拥有包括仪器销售,试剂销售,市场与技术支持,维修,客服,物流等多个部门组成的完整服务体系。 我们希望通过不懈努力,为您的成功铺路搭桥,也为中国的生命科学事业赶超世界先进水平尽一己之力。欲了解更多信息,请访问www.genecompany.cn。










